Le YASEP n'a pas d'instructions de lecture ou d'écriture en mémoire. Contrairement à l'écrasante majorité des processeurs existants (de la catégorie "Load-Store architecture"), il accède à la mémoire au travers des registres, plus ou moins comme le faisait le CDC6600 (sauf que les registres du YASEP ne sont pas dédiés à l'écriture ou la lecture). Cela économise des opcodes, augmente le nombre d'accès mémoire par intruction, et garde la structure des instructions très orthogonale.
L'architecture du YASEP est conçue autour de 16 registres répartis en 4 types. Voici la liste des noms, avec leur numéro :
C'est un peu plus compliqué qu'une architecture RISC classique mais cela réduit le nombre d'opcodes en leur permettant de remplir de nombreuses fonctions différentes. Il existe aussi deux bits de condition (Carry/retenue et Equal/égal) mais ils sont accessibles seulement au travers des instructions conditionnelles. Le mécanisme de sauvegarde et la restauration de l'état en cas d'exception n'est pas encore déterminé.
R1, R2, R3, R4 et R5 sont des registres normaux. Comme dans les autres architectures, ils sont lus et écrits sans déclencher d'action implicite.
; Exemple 1 MOV 1234h R2 ; écrit la valeur 1234h dans le registre R2 ; Exemple 2 ADD 4 R1 ; R1 <- R1 + 4 ; Exemple 3 ADD 42 R1 R3 ; R3 <- R1 + 42
On les utilise pour contenir les résultats intermédiaires des calculs, les compteurs de boucles, les paramètres d'appel aux fonctions... Les formes d'instructions étendues permettent aussi de les post-incrémenter ou post-décrémenter.
Ce registre est plus spécial : PC est le pointeur vers l'instruction en cours. Les lettres "PC" signifient "Program Counter". Il est automatiquement incrémenté à chaque nouvelle instruction, et peut être lu et sur-écrit par toutes les instructions.
; Exemple : ADD 1234h PC A1 ; charge l'adresse PC+1234h dans A1
; Exemple 1 MOV 1234h PC ; Saute à l'addresse 1234h ; Exemple 2 ADD 4 PC ; Saute à PC+4 ; Exemple 3 ADD R1 32 PC ; Saute à R1+32
On peut remarquer que les instructions de YASEP sont encodées sur 2 ou 4 octets et que toutes les adresses ont une granularité d'un octet. De plus, les instructions sont toujours à des adresses paires, donc le bit de poids faible des adresses d'instructions est toujours implicitement à 0.
Cependant, il ne faut pas se fier à cette particularité car cela pourra changer dans le futur. En attendant, au mieux, l'écriture d'un 1 dans le bit de poids faible peut être ignorée, au pire cela peut bloquer le processeur, le réinitialiser ou déclencher une interruption, selon l'implémentation. Donc gardez ce bit à 0 !
Les registres A1, A2, A3, A4 et A5 contiennent l'adresse où une donnée sera lue ou écrite en mémoire. Ils peuvent être mis à jour (post-incrémentés ou post-décrémentés) par les instructions de forme étendue, afin d'accéder facilement à des données contigües.
D1, D2, D3, D4 et D5 sont des registres de données, associés aux registres d'adresse : A1 est lié à D1, A2 à D2 etc. Le YASEP maintient toujours la cohérence entre les registres d'adresse et de donnée d'une paire, afin de préserver la relation Dx=memoire[Ax] (sauf en cas d'alias des pointeurs) :
Si on écrit et lit le même registre de donnée (qui est alors utilisé comme opérande et destination), alors cela met à jour la mémoire. C'est une manière de faire des opérations "RMW" (read-modify-write) avec un cœur RISC orthogonal.
; Exemple 1
MOV 1234h A1 ; pointe A1 vers l'addresse 1234h ==> D1 contient la valeur à cette adresse.
ADD D1 R3 ; ajoute le contenu de la mémoire à l'adresse 1234 au registre R3.
; Exemple 2
ADD 1234h R1 A4 ; additionne R1+1234h et met le résultat dans A4 ==> D4 contient la valeur à cette adresse.
ADD R2 D4 ; lit le mot situé à l'adresse [R1+1234h],
; ajoute la valeur de R2 et réécrit le résultat à la même adresse.
En conjonction avec les fonctions d'incrémentation et décrémentation, ces registres peuvent réaliser des piles. Par convention, A5 est le pointeur de pile et D5 est le sommet de la pile, mais rien n'empêche de créer 2 ou 3 piles, ou bien de réaliser la pile standard avec d'autres registres
Lorsque deux registres d'Adresses (ou plus) pointent vers le même mot en mémoire, il ne faut pas s'attendre à ce que les valeurs des registres de Données restent cohérents après une écriture. Par exemple, dans le cas où A1=A2, alors une écriture dans D1 ne va pas automatiquement mettre à jour la valeur de D2.
Pour les premières réalisations, il n'est pas raisonnable de comparer 5 registres d'Adresses entre eux et d'écrire conditionnellement 5 registres de données. La longueur du pipeline ainsi que le nombre de portes logiques augmenteraient beaucoup trop ! Dans les cas les plus simples, on peut considérer que le banc de registre sert de tampon à la mémoire, ce qui permet de conserver l'état même lors de changements de contextes.
Cependant il est possible et même probable que des réalisations plus sophistiquée résolvent le problème, au moyen de structures différentes. Selon le cas, le banc de registre complet doit être préservé durant des changements de contexte.
Dans tous les cas, des concurrences critiques peuvent se produire. Lorsqu'un alias ou chevauchement de pointeurs est attendu ou même simplement possible, il ne faut pas hésiter à utiliser une section critique (voir l'opcode CRIT) et le plus sûr est de n'utiliser qu'une seule paire de registres Adresse/Donnée pour accéder à ces mots en mémoire. Comme l'a montré l'exemple précédent, les opérations de "read-modify-write" fonctionnent mieux et sont plus courtes lorsqu'une seule paire est utilisée.
Le YASEP est une architecture Little-Endian : l'octet de poids faible est stocké dans l'adresse la plus basse du mot. Au besoin, l'instruction BSWAP inverse l'ordre des octets dans un registre.
Une version Big-Endian pourrait être envisagée sous le nom de code PESAY, bien que cela se limite juste à une case à cocher dans le configurateur, qui changerait l'ordre des octets sur le bus de données.
Les pointeurs du YASEP peuvent adresser des octets mais TOUS les accès à la mémoire sont physiquement alignés sur la taille des registres.
Les accès non alignés ne provoquent pas d'erreur ou d'exception. Les registres de données contiennent une copie de la mémoire, sans décalage, telle que vue sur le bus de données.
On pourrait même schématiser de cette manière :
Les bits "inutilisés" servent juste à sélectionner un octet dans le (demi-)mot.
; Exemple 1 (lecture en mémoire) MOV 1231h A5 ; pointe A5 vers l'addresse 1231h (impaire donc non alignée) MOV D5 R2 ; copie le mot à l'adresse 1230 dans R2. ; Exemple 1 bis (YASEP32 seulement) MOV 1232h A1 ; pointe A1 vers l'addresse 1232h (non alignée sur une frontière de mot) MOV D1 R1 ; copie le mot à l'adresse 1230 dans R1. ; Exemple 2 (écriture en mémoire) MOV 1231h A2 ; pointe A2 vers l'addresse 1231h (impaire donc non alignée) MOV R2 D2 ; écrit R2 en mémoire à l'adresse 1230 ; Exemple 2 bis (YASEP32 seulement) MOV 1232h A3 ; pointe A3 vers l'addresse 1232h (non alignée sur une frontière de mot) MOV R4 D3 ; écrit R4 en mémoire à l'adresse 1230
Si on traite des octets ou demis-mots, l'alignement peut être effectué automatiquement par certaines instructions :
; Exemple 3 (lecture en mémoire) MOV 1231h A5 ; pointe A5 vers l'addresse 1231h (impaire donc non alignée) ESB D5 R2 ; Extrait l'octet à l'adresse 1231, étend le bit de signe et écrit le résultat dans R2. ; Exemple 3 bis (YASEP32 seulement) MOV 1232h A1 ; pointe A1 vers l'addresse 1232h (non alignée sur une frontière de mot) ESH D1 R1 ; Extrait le demi-mot à l'adresse 1232, étend le bit de signe et écrit le résultat dans R1. ; Exemple 4 (écriture en mémoire) MOV 1231h A2 ; pointe A2 vers l'addresse 1231h (impaire donc non alignée) IB R2 D2 ; prend l'octet de poids faible en R2, insère le résultat dans l'octet de poids fort de D2. ; Exemple 4 bis (YASEP32 seulement) MOV 1232h A3 ; pointe A3 vers l'addresse 1232h (non alignée sur une frontière de mot) IH R4 D3 ; prend le demi-mot de poids faible en R4, insère le résultat dans le demi-mot de poids fort de D3.
Comme la plupart des ordinateurs, le YASEP travaille mieux lorsque les données sont correctement alignées en mémoire. Au moindre doute, les programmes doivent vérifier l'alignement des pointeurs.
Les mots ou demi-mots non alignés doivent être reconstitués au moyen de séquences d'instructions appropriées, dont voici quelques exemples..
Comme c'est expliqué dans la partie ci-dessus, YASEP16 et YASEP32 accèdent aux octets d'un mot avec les instructions ESB, EZB et IB. Les octets ne peuvent pas chevaucher une frontière de mot donc il n'y a pas de traitement supplémentaire.
Le YASEP16 dispose juste de ESB, EZB et IB. Des octets consécutifs peuvent être combinés avec l'opcode SHLO.
Le YASEP32 a aussi ESH, EZH et IH qui sont plus adaptés. Ils mettent à 1 le flag Carry pour indiquer que l'opération d'insertion/extraction dépasse du mot.
Pour accéder à un demi-mot stocké à une adresse paire (lorsque la condition LSB0 sur le pointeur est vraie), YASEP16 peut y accéder directement et YASEP32 peut utiliser une seule instruction d'Insertion/Extraction. Au contraire, si l'adresse est impaire, il faut utiliser une séquence d'instructions pour assembler/désassembler les octets.
; écriture d'un demi-mot non aligné de R1 vers A1/D1 ; R1 est modifié IB A1 R1 D1+ ; écriture de l'octet de poids faible ROR 8 R1 IB A1 R1 D1- ROL 8 R1 ; éventuellement, si on veut réutiliser R1 ; lecture d'un demi-mot non aligné non signé de A1 vers R1 ; R2 est un registre temporaire EZB A1 D1+ R1 ; lecture du LSByte EZB A1 D1- R2 ; lecture du MSByte SHLO 8 R2 R1 ; Combine le MSByte dans le LSByte ; lecture d'un demi-mot non aligné signé de A1 vers R1 ; R2 est un registre temporaire EZB A1 D1+ R1 ; lecture du LSByte ESB A1 D1- R2 ; lecture et extension du signe du MSByte SHLO 8 R2 R1 ; Combine le MSByte dans le LSByte
Pour le YASEP32, il existe deux cas : soit l'adresse est paire, et alors on peut utiliser les instructions qui traitent des demis-mots, soit elle est impaire et il faut gérer le mot octet par octet, ce qui est encore plus lent.
; lecture d'un mot non aligné de A1 vers R1 avec YASEP32 ; R2 est un registre temporaire EZB A1 D1+ R1 ; lecture du LSByte EZB A1 D1+ R2 ; SHLO 8 R2 R1 ; Combine dans le LSByte EZB A1 D1+ R2 ; SHLO 16 R2 R1 ; EZB A1 D1+ R2 ; lecture du MSByte SHLO 24 R2 R1 ; ADD -3 A1 ; optionel ; lecture d'un mot à une adresse paire avec YASEP32 ; R2 est un registre temporaire EZH A1 D1+ R1 ; lecture du LSHW EZH A1 D1- R2 ; lecture du MSHW SHLO 16 R2 R1 ; Combine le MSHW dans le LSHW
(ajouté au blog le mardi 8 Novembre 2011)
(mise à jour 2013-08-09 : ajouté à YASim et simplifié)
Comme dit plus haut, l'architecture du YASEP spécifie 5 registres "normaux" et 5 paires de registres adresses/données (A1/D1, A2/D2...) et il est assez difficile de trouver un équilibre entre ces nombres, car chaque application et chaque cas requiert un nombre différent de registres.
Si plus de registres normaux sont nécessaires (imaginons qu'on aie besoin de R6 et R7) alors on pourrait les assigner à D1 et D2 par exemple. Cependant, auparavant, il faut donner des adresses convenables à A1 et A2, sinon le programme pourrait planter à cause de valeurs aléatoires (ou pire) dans A1 et A2, ce qui écrirait D1 et D2 n'importe où...
Une autre situation indésirable pourrait se produire si on se sert de A1 et A2 comme registres de données. Chaque écriture déclencherait une lecture de la mémoire. Si en plus un système de mémoire paginée est utilisé, chaque écriture risque de déclencher une faute de page (ou de protection), ce qui ralentirait considérablement le programme...
Il existe une approche assez radicale : un bit par paire de registres pourrait définir si la paire est utilisée pour accéder à la mémoire ou comme registres normaux. L'avantage de cette approche est qu'il est possible de libérer deux registres d'un coup, mais c'est compliqué à utiliser avec un compilateur ou au niveau d'un code source de haut niveau. En plus il faut sauver 5 bits supplémentaires lors d'un changement de contexte, ce qui peut devenir un vrai cauchemar...
Dans le YASEP, une autre technique, appelée "parking", est utilisée. Elle est moins optimale mais plus pratique et moins coûteuse : la valeur particulière -1 dans tout registre A va inhiber les accès à la mémoire pour le registre D associé. On perd un registre mais le système reste disponible : on n'a pas besoin d'une instruction supplémentaire pour accéder de nouveau à la mémoire, il suffit de mettre une nouvelle adresse valide dans le registre A.
Une paire de registres est "parquée" lorsque son registre A a tous ses bits à 1 (soit la valeur -1). Lorsqu'on écrit -1 dans un registre A, le registre D associé garde sa valeur précédente mais n'accède plus à la mémoire et donc on peut y écrire autant qu'on veut.
Cette adresse négative correspond à une zone "tout en haut" de la carte mémoire, qui n'est pas nécessairement implémentée, ou alors réservée à des constantes adressées par des adresses immédiates courtes (de -8 à +7) :
MOV 6, A3 ; mem[6] contient une constante utile
; ou une variable récurrente
MOV D3,... ; dont l'adresse tient sur 4 bits
Attention car toutes les implémentations du YASEP ne supportent pas le parking.
Ces profils le supportent : (not initialised)
Et ceux-cis non : (not initialised)
Voici un exemple qui parque tous les registres :
MOV -1 A1
MOV -1 A2 ; n'oubliez pas de sauver l'adresse
MOV -1 A3 ; de la pile à un endroit bien connu
MOV -1 A4 ; sinon vous ne pourrez plus reprendre
MOV -1 A5 ; la suite du programme...
Vous pouvez toujours accéder au (demi-)mot à l'adresse -1 en utilisant une adresse paire, car tous les accès à la mémoire ignorent le bit de poids faible de l'adresse. Donc le mot est aussi accessible à l'adresse -2 pour YASEP16 et -4 pour YASEP32.
Cela signifie aussi que sur une architecture qui ne supporte pas le parking, en supposant que la RAM y soit accessible, on peut avoir au maximum une paire "parquée" sans risque de corruption dûe au parking d'une autre paire. On peut toujours réaliser un "parking" logiciel en allouant une zone mémoire dédiée, mais avec le coût d'accès intempstifs à la mémoire.
Au niveau de l'architecture, cela ne change quasiment rien. Les registres de données sont habituellement "cachés" au niveau du banc de registre. Ce que le système de garage ajoute, c'est juste l'inhibition du signal d'écriture vers la mémoire, qui serait normalement actif à chaque fois qu'on écrit dans le registre de données.
En ce qui concerne la sauvegarde et la restauration des registres d'un thread,
différentes approches sont possibles.
* Si le système de parking n'est pas disponible, alors sauver le registre d'adresse suffit
car le registre de donnée correspondant sera remis à la bonne valeur en relisant
la mémoire lors de la restauration en supposant qu'il n'y ait pas d'aliasing.
* Si le parking est implémenté alors il faut aussi conserver la valeur du registre D,
mais ne le restaurer que si le registre A est à -1 (autrement cela risque
d'altérer la mémoire qui a pu être modifiée entretemps).
Finalement, le parking n'ajoute que quelques portes logiques pour inhiber les accès à la mémoire si des registres ont une certaine valeur. Pour le programmeur, cela veut dire qu'il est possible d'avoir plus de registres de données, au détriment des accès à la mémoire. Il est possible alors d'avoir R6, R7 et R8 mais il faudra renoncer à l'utilisation de A1/D1, A2/D2 et A3/D3. À vous de choisir !
La retenue est un registre d'un bit qui mémorise la retenue de la dernière instruction ADD ou SUB executée. Le bit de retenue est mis à 1 lorsqu'une addition dépasse la largeur des registres :
.profile YASEP16 MOV 5678h R1 ADD CDEFh R1 R2 ; R2 <- 5678h + CDEFh = 12467h > FFFFh donc "carry" mis à 1 ADD 1234h R1 R2 ; R2 <- 5678h + 1234h = 68ACh <= FFFFh donc "carry" mis à 0
Le bit "carry" peut ensuite être testé par une instruction conditionnelle :
ADD 1234h R1 ; R1 <- R1 + 1234h (change la retenue) ADD 5 R2 CARRY ; Si la retenue est égale à 1, alors on additionne R2 et 5
L'instruction SUB est basée sur l'addition et donc utilise le même bit de retenue que ADD. Cependant, pour SUB, la valeur du bit est inversée, ce dernier est à 1 lorsque la soustraction n'a pas généré de retenue :
MOV 4 R1 SUB 3 R1 R2 ; R2 = 3 - 4 = -1 ==> carry=0 SUB 4 R1 R2 ; R2 = 4 - 4 = 0 ==> carry=1 SUB 5 R1 R2 ; R2 = 5 - 4 = 1 ==> carry=1
Seules les instructions marquées par le flag "CHANGE_CARRY" peuvent changer le bit de retenue. Parmi celles-cis on trouve CMPU et CMPS, qui sont comme l'instruction SUB mais qui n'écrivent pas le résultat de la soustraction. Il y a aussi ESH EZH et IH qui indiquent un alignement qui dépasse du mot, en mettant ce bit à 1. Toutes les autres instructions préserveront ce bit.
La retenue peut donc être testée de nombreux cycles après l'exécution de ADD/SUB/CMPU/CMPS, même après des appels ou des retours de fonctions. La meilleure manière de forcer la valeur de la retenue est d'utiliser astucieusement les instructions CMPU ou CMPS, avec des opérandes qui donneront toujours le même résultat :
; mettre la retenue à 0 : CMPU R1, R1 ; R1 est égal à R1 donc le flag ne peut pas être à 1. ; mettre la retenue à 1 : CMPU 0, PC ; PC est (quasiment) toujours supérieur à 0 donc la retenue est forcément à 1. ; (devrait devenir une macro/substitution)
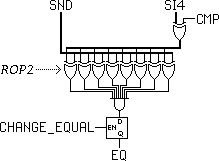
Comme pour le bit de retenue, le bit Égal est mis à jour par les opcodes marqués avec le flag CHANGE_EQUAL.
C'est complémentaire avec la condition "Zero" qui peut tester presque tous les registres. Cependant, comme il y a très peu de registres (et souvent aucune place pour un résultat temporaire de comparaison), certaines instructions n'écrivent par le résultat du calcul dans un registre : CMPU/CMPS.
Le flag est calculé en réutilisant une partie des portes logiques de ROP2 et est le résultat du XOR bit à bit des deux opérandes, suivi par une réduction par AND. Ainsi, le flag est à 1 lorsque les deux opérandes sont identiques. Il est accessible uniquement au moyen des conditions EQ et NEQ.